Libra is a temporally-aware multimodal large language model designed for chest X-ray report generation. By leveraging temporal sequences of medical images, Libra enhances the understanding of disease progression and improves the accuracy of automated radiology report generation. This approach aids clinicians by providing more context-aware and consistent reporting over time. For the latest updates and details, please visit the project website.
CancerMine
This project uses natural language processing to identify cancer genes and their roles in different cancers (e.g. as drivers, oncogenes or tumor suppressors). This information can be used to help identify important cancer mutations and understanding the underlying genetics of different cancer types. This work was published in Nature Methods. The dataset can be explored through this web viewer, the code is available at GitHub and the dataset is available at Zenodo
CIViCmine
Precision oncology enables scientists and clinicians to probe the genetics of individual patients’ tumours. But the clinical relevance of each mutation can be hard to ascertain and reference to the latest research is often required. The CIViC database aims to curate this expert knowledge. As part of this, the CIViCmine project uses natural language processing to identify mentions of cancer mutations and their clinical impacts. This work was published in Genome Medicine. The dataset can be explored through this web viewer, the code is available at GitHub and the dataset is available at Zenodo.
CoronaCentral
During the coronavirus pandemic, a vast number of research papers were published related to COVID-19. The Corona Central resource categorized these using a BERT-based classifier along with a unique dataset of categorized documents. It provided a portal to explore these research papers. This work was published in PNAS. The code can be accessed at GitHub and the corpus of documents at Zenodo.
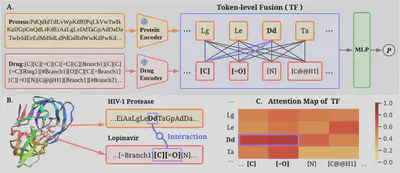
FusionDTI
Predicting drug-target interaction (DTI) is critical in the drug discovery process. Despite remarkable advances in recent DTI models through the integration of representations from diverse drug and target encoders, such models often struggle to capture the fine-grained interactions between drugs and protein. To address this issue, we introduce a novel model, called FusionDTI, which uses a token-level Fusion module to effectively learn fine-grained information for Drug-Target Interaction. This work was published in ICML 2024 AI for Science Workshop. The code can be accessed at GitHub and the demo at Hugging Face.
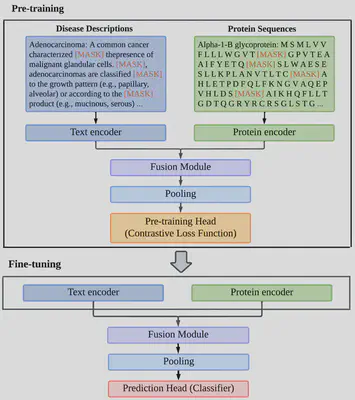
FusionGDA
Identifying associations between genes and diseases is critical for diagnosis, prevention, prognosis and drug development. We propose a novel FusionGDA model, which utilises a pre-training phase with a fusion module to enrich the gene and disease semantic representations encoded by pre-trained language models. This work was published in Briefings in Bioinformatics. The code can be accessed at GitHub and the demo at Hugging Face.
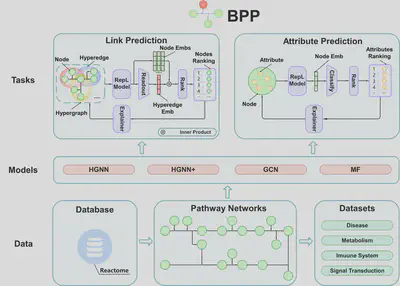
BPP
Biological pathways are a series of interconnected biochemical reactions that support life activities. Current research relies heavily on experiments and manual analysis, overlooking the rich topological information within pathway networks. We develop a Biochemical Pathway Prediction (BPP) platform to automatically identify potential connections within these pathways. BPP can predict participants or products in biochemical reactions and includes tools to interpret these predictions. This work was published in Briefings in Bioinformatics. The website and code can be accessed at GitHub.